
2011.1.21 微信正式发布。这一天距离微信项目启动日约为2个月。就在这2个月里,微信从无到有,大家可能会好奇这期间微信后台做的最重要的事情是什么?
我想应该是以下三件事:
微信起初定位是一个通讯工具,作为通讯工具最核心的功能是收发消息。微信团队源于广硏团队快速裂变,消息模型跟邮箱的邮件模型也很有渊源,都是存储转发。
图 1 微信消息模型
上图展示了这一消息模型,消息被发出后,会先在后台临时存储;为使接收者能更快接收到消息,会推送消息通知给接收者;最后客户端主动到服务器收取消息。
由于用户的帐户、联系人和消息等数据都在服务器存储,如何将数据同步到客户端就成了很关键的问题。为简化协议,我们决定通过一个统一的数据同步协议来同步用户所有的基础数据。
最初的方案是客户端记录一个本地数据的快照(Snapshot),需要同步数据时,将Snapshot带到服务器,服务器通过计算Snapshot与服务器数据的差异,将差异数据发给客户端,客户端再保存差异数据完成同步。不过这个方案有两个问题:一是Snapshot会随着客户端数据的增多变得越来越大,同步时流量开销大;二是客户端每次同步都要计算Snapshot,会带来额外的性能开销和实现复杂度。
几经讨论后,方案改为由服务计算Snapshot,在客户端同步数据时跟随数据一起下发给客户端,客户端无需理解Snapshot,只需存储起来,在下次数据同步数据时带上即可。同时,Snapshot被设计得非常精简,是若干个Key-Value的组合,Key代表数据的类型,Value代表给到客户端的数据的最新版本号。Key有三个,分别代表:帐户数据、联系人和消息。这个同步协议的一个额外好处是客户端同步完数据后,不需要额外的ACK协议来确认数据收取成功,同样可以保证不会丢数据:只要客户端拿最新的Snapshot到服务器做数据同步,服务器即可确认上次数据已经成功同步完成,可以执行后续操作,例如清除暂存在服务的消息等等。
此后,精简方案、减少流量开销、尽量由服务器完成较复杂的业务逻辑、降低客户端实现的复杂度就作为重要的指导原则,持续影响着后续的微信设计开发。记得有个比较经典的案例是:我们在微信1.2版实现了群聊功能,但为了保证新旧版客户端间的群聊体验,我们通过服务器适配,让1.0版客户端也能参与群聊。
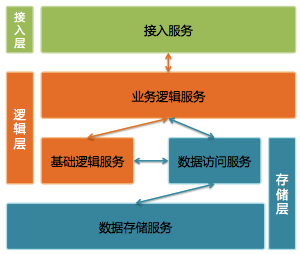

图 2 微信后台系统架构
微信后台使用三层架构:接入层、逻辑层和存储层
微信后台主要使用C++。后台服务使用Svrkit框架搭建,服务之间通过同步RPC进行通讯。
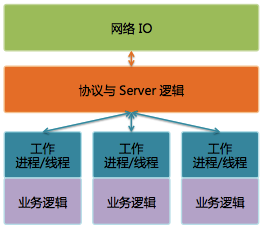
图 3 Svrkit 框架
Svrkit是另一个广硏后台就已经存在的高性能RPC框架,当时尚未广泛使用,但在微信后台却大放异彩。作为微信后台基础设施中最重要的一部分,Svrkit这几年一直不断在进化。我们使用Svrkit构建了数以千计的服务模块,提供数万个服务接口,每天RPC调用次数达几十万亿次。
这三件事影响深远,乃至于5年后的今天,我们仍继续沿用最初的架构和协议,甚至还可以支持当初1.0版的微信客户端。
这里有一个经验教训——运营支撑系统真的很重要。第一个版本的微信后台是仓促完成的,当时只是完成了基础业务功能,并没有配套的业务数据统计等等。我们在开放注册后,一时间竟没有业务监控页面和数据曲线可以看,注册用户数是临时从数据库统计的,在线数是从日志里提取出来的,这些数据通过每个小时运行一次的脚本(这个脚本也是当天临时加的)统计出来,然后自动发邮件到邮件组。还有其他各种业务数据也通过邮件进行发布,可以说邮件是微信初期最重要的数据门户。
2011.1.21 当天最高并发在线数是 491,而今天这个数字是4亿。
在微信发布后的4个多月里,我们经历了发布后火爆注册的惊喜,也经历了随后一直不温不火的困惑。
这一时期,微信做了很多旨在增加用户好友量,让用户聊得起来的功能。打通腾讯微博私信、群聊、工作邮箱、QQ/邮箱好友推荐等等。
对于后台而言,比较重要的变化就是这些功能催生了对异步队列的需求。例如,微博私信需要跟外部门对接,不同系统间的处理耗时和速度不一样,可以通过队列进行缓冲;群聊是耗时操作,消息发到群后,可以通过异步队列来异步完成消息的扩散写等等。
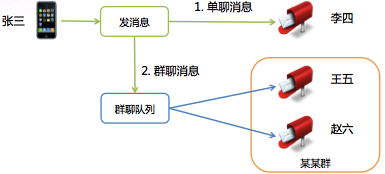
图 4 单聊和群聊消息发送过程
图4是异步队列在群聊中的应用。微信的群聊是写扩散的,也就是说发到群里的一条消息会给群里的每个人都存一份(消息索引)。
微信的群聊为什么不是读扩散呢?有两个原因:
异步队列作为后台数据交互的一种重要模式,成为了同步RPC服务调用之外的有力补充,在微信后台被大量使用。
微信的飞速发展是从2.0版开始的,这个版本发布了语音聊天功能。之后微信用户量急速增长,2011.5用户量破100万、2011.7 用户量破1000万、2012.3 注册用户数突破1亿。
伴随着喜人成绩而来的,还有一堆幸福的烦恼:
后台稳定性的要求:
用户多了,功能也多了,后台模块数和机器量在不断翻番,紧跟着的还有各种故障。
帮助我们顺利度过这个阶段的,是以下几个举措:
虽然各种需求扑面而来,但我们每个实现方案都是一丝不苟完成的。实现需求最大的困难不是设计出一个方案并实现出来,而是需要在若干个可能的方案中,甄选出最简单实用的那个。
这中间往往需要经过几轮思考——讨论——推翻的迭代过程,谋定而后动有不少好处,一方面可以避免做出华而不实的过度设计,提升效率;另一方面,通过详尽的讨论出来的看似简单的方案,细节考究,往往是可靠性最好的方案。
逻辑层的业务逻辑服务最早只有一个服务模块(我们称之为mmweb),囊括了所有提供给客户端访问的API,甚至还有一个完整的微信官网。这个模块架构类似Apache,由一个CGI容器(CGIHost)和若干CGI组成(每个CGI即为一个API),不同之处在于每个CGI都是一个动态库so,由CGIHost动态加载。
于是我们开始尝试使用一种新的CGI架构——Logicsvr:
Logicsvr基于Svrkit框架。将Svrkit框架和CGI逻辑通过静态编译生成可直接使用HTTP访问的Logicsvr。我们将mmweb模块拆分为8个不同服务模块。拆分原则是:实现不同业务功能的CGI被拆到不同Logicsvr,同一功能但是重要程度不一样的也进行拆分。例如,作为核心功能的消息收发逻辑,就被拆为3个服务模块:消息同步、发文本和语音消息、发图片和视频消息。
每个Logicsvr都是一个独立的二进制程序,可以分开部署、独立上线。时至今日,微信后台有数十个Logicsvr,提供了数百个CGI服务,部署在数千台服务器上,每日客户端访问量几千亿次。
除了API服务外,其他后台服务模块也遵循“大系统小做”这一实践准则,微信后台服务模块数从微信发布时的约10个模块,迅速上涨到数百个模块。
这一时期,后台故障很多。比故障更麻烦的是,因为监控的缺失,经常有些故障我们没法第一时间发现,造成故障影响面被放大。
监控的缺失一方面是因为在快速迭代过程中,重视功能开发,轻视了业务监控的重要性,有故障一直是兵来将挡水来土掩;另一方面是基础设施对业务逻辑监控的支持度较弱。基础设施提供了机器资源监控和Svrkit服务运行状态的监控。这个是每台机器、每个服务标配的,无需额外开发,但是业务逻辑的监控就要麻烦得多了。
当时的业务逻辑监控是通过业务逻辑统计功能来做的,实现一个监控需要4步:
可以想象,这种费时费力的模式会反过来降低开发人员对加入业务监控的积极性。于是有一天,我们去公司内的标杆——即通后台(QQ后台)取经了,发现解决方案出乎意料地简单且强大:
【故障报告】
之前每次故障后,是由QA牵头出一份故障报告,着重点是对故障影响的评估和故障定级。新的做法是每个故障不分大小,开发人员需要彻底复盘故障过程,然后商定解决方案,补充出一份详细的技术报告。这份报告侧重于:如何避免同类型故障再次发生、提高故障主动发现能力、缩短故障响应和处理过程。
【基于 ID-Value 的业务无关的监控告警体系】
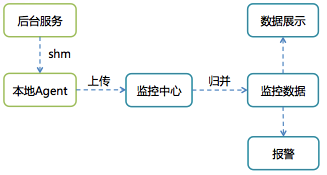
图 5 基于 ID-Value 的监控告警体系
监控体系实现思路非常简单,提供了2个API,允许业务代码在共享内存中对某个监控ID进行设置Value或累加Value的功能。每台机器上的Agent会定时将所有ID-Value上报到监控中心,监控中心对数据汇总入库后就可以通过统一的监控页面输出监控曲线,并通过预先配置的监控规则产生报警。
对于业务代码来说,只需在要被监控的业务流程中调用一下监控API,并配置好告警条件即可。这就极大地降低了开发监控报警的成本,我们补全了各种监控项,让我们能主动及时地发现问题。新开发的功能也会预先加入相关监控项,以便在少量灰度阶段就能直接通过监控曲线了解业务是否符合预期。
微信后台每个存储服务都有自己独立的存储模块,是相互独立的。每个存储服务都有一个业务访问模块和一个底层存储模块组成。业务访问层隔离业务逻辑层和底层存储,提供基于RPC的数据访问接口;底层存储有两类:SDB和MySQL。
SDB适用于以用户UIN(uint32_t)为Key的数据存储,比方说消息索引和联系人。优点是性能高,在可靠性上,提供基于异步流水同步的Master-Slave模式,Master故障时,Slave可以提供读数据服务快速裂变,无法写入新数据。
由于微信账号为字母+数字组合,无法直接作为SDB的Key,所以微信帐号数据并非使用SDB,而是用MySQL存储的。MySQL也使用基于异步流水复制的Master-Slave模式。
KVSvr使用基于Quorum的分布式数据强一致性算法,提供Key-Value/Key-Table模型的存储服务。传统Quorum算法的性能不高,KVSvr创造性地将数据的版本和数据本身做了区分,将Quorum算法应用到数据的版本的协商,再通过基于流水同步的异步数据复制提供了数据强一致性保证和极高的数据写入性能,另外KVSvr天然具备数据的Cache能力,可以提供高效的读取性能。
KVSvr一举解决了我们当时迫切需要的无单点故障的容灾能力。除了第5版的帐号服务外,很快所有SDB底层存储模块和大部分MySQL底层存储模块都切换到KVSvr。随着业务的发展,KVSvr也不断在进化着,还配合业务需要衍生出了各种定制版本。现在的KVSvr仍然作为核心存储,发挥着举足轻重的作用。
本文来自投稿,不代表重蔚自留地立场,如若转载,请注明出处https://www.cwhello.com/168821.html
如有侵犯您的合法权益请发邮件951076433@qq.com联系删除